Déployer vLLM sur OVHcloud MKS pour l’inférence vision-langage Déploiement d’un modèle vision-langage avec vLLM sur OVHcloud MKS pour une inférence scalable et une observabilité complète.
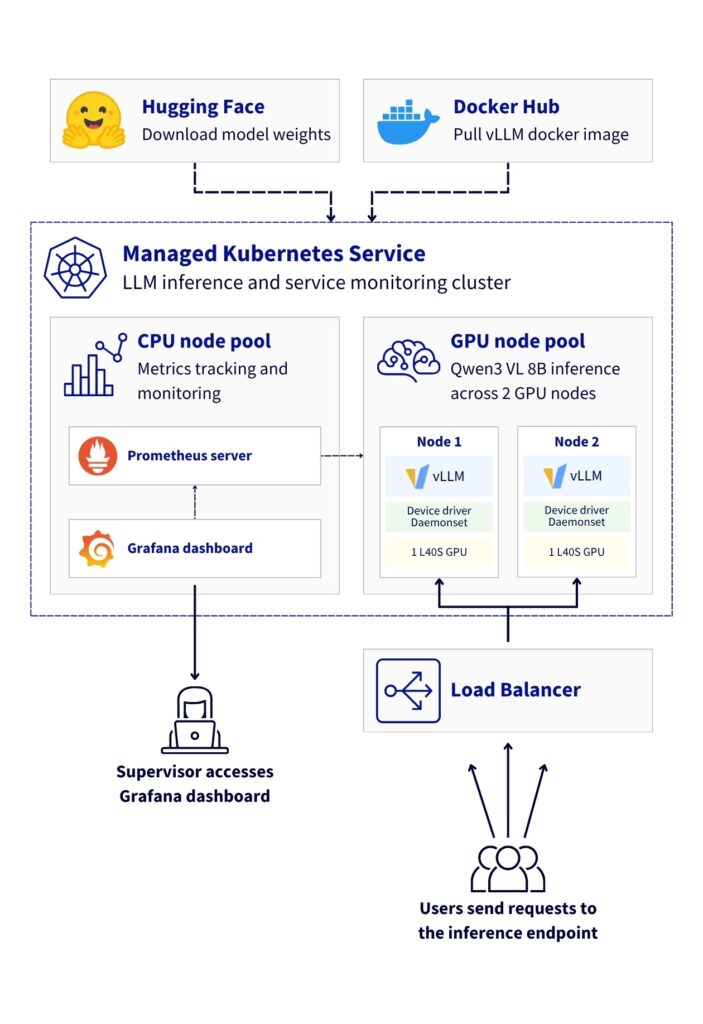
Pour assurer une souveraineté numérique des IA, le duo vLLM OVHcloud MKS illustre le déploiement d’un modèle vision-langage sur une plateforme Kubernetes gérée, avec des GPU NVIDIA L40S et des endpoints OpenAI‑compatibles. Cette architecture de référence montre comment déployer, scaler et surveiller des charges d’inférence LLM grâce à vLLM sur OVHcloud MKS, tout en restant dans des datacenters européens.
Contexte et bénéfices
OVHcloud MKS est une plateforme Kubernetes entièrement gérée qui réduit les charges opérationnelles tout en assurant sécurité et disponibilité.
Les bénéfices incluent une réduction des coûts via des services managés, une observabilité en temps réel (TTFT, throughput, utilisation des ressources) et une architecture prête à évoluer, tout en garantissant la souveraineté des données.
Architecture et flux de données
La solution s’appuie sur un flux clair pour l’inférence : utilisateur → Load Balancer → Gateway → NGINX Ingress → service qwen3-vl → pod vLLM → GPU. La réponse peut s’effectuer en streaming. Côté métriques, les pods vLLM exposent /metrics sur le port 8000 et les DCGM Exporters sur le port 9400; Prometheus interroge ces endpoints toutes les 30 secondes et Grafana offre les dashboards.
- Affinités et répartition : cookie-based et ClientIP pour diriger les sessions vers les nœuds et équilibrer les charges, avec anti-affinité pour limiter l’utilisation d’un seul nœud.
- Surveillance GPU : DCGM collecte les métriques comme utilisation, température et mémoire utilisée.
Mise en œuvre et étapes clés
Le déploiement s’effectue en plusieurs temps, depuis la préparation de l’infrastructure jusqu’au déploiement du modèle avec vLLM et l’exposition de l’API OpenAI‑compatible.
- Étape 1 : création du cluster MKS et des pools de nœuds, avec deux nœuds L40S pour le calcul et un pool CPU pour la supervision.
- Étape 2 : installation de l’opérateur GPU et configuration des exporters DCGM, en veillant à une version compatible avec CUDA 12.x.
- Étape 3 : déploiement du modèle Qwen3‑VL‑8B via le serveur d’inférence vLLM et démarrage des pods.
- Étape 4 : mise en place de l’Ingress NGINX et exposition de l’API, puis vérification d’accès et des endpoints.
- Étape 5 et suivantes : mise en place des dashboards Prometheus et Grafana et des ServiceMonitors pour vLLM et DCGM, afin d’obtenir une vue unifiée.
Observabilité et limites
La solution offre une observabilité complète des applications et du matériel via Grafana et des dashboards dédiés. Des limites potentielles incluent la gestion des tokens Hugging Face et les dépendances entre versions de pilotes et images conteneurs, qui nécessitent des tests et ajustements.
Pour terminer
Cette architecture démontre qu’un déploiement vLLM OVHcloud MKS peut offrir une inférence rapide et une visibilité opérationnelle robuste, tout en restant conforme aux exigences de souveraineté. Surveillez les métriques et ajustez les ressources selon la charge.


